go言語で複数のgoroutineのleakを検出する(goleak使用)
関連
概要
goleakパッケージでのgoroutine leakを検出してみました。
goroutine数の確認
runtime package - runtime - Go Packages
上のパッケージを使って、goroutineの数を調べてみます。
何もしないmain関数
printlnするだけのmainのgoroutine数を調べてみます。
https://goplay.tools/snippet/TO3jpRrT8Ju
package main import "runtime" func main() { println(runtime.NumGoroutine()) }
私の環境では、1とでました。
main関数だけなのでこれは納得です。
Test関数
次にテスト関数でgoroutine数を調べてみます
https://goplay.tools/snippet/kPaUslIP_R1
package main import ( "fmt" "runtime" "testing" ) func TestSample(t *testing.T) { fmt.Println("num goroutine: ", runtime.NumGoroutine()) }
=== RUN TestSample num goroutine: 2 --- PASS: TestSample (0.00s) PASS
私の環境では2とでました。
ここで2となる理由については詳しく調べませんが、runtime.main()以外にも他のgoroutineが動いていることがあり、
それが検出されているそうです。
参考にさせていただ記事: jxck.hatenablog.com
goroutineを起動(leakしないけど不安なコード)
ここから本題です。
文字列に「a1」とつけて返す関数GetResourceAをgoroutineで起動して終了を待つ関数Executeを作り、
各所でgoroutine数を測ってみます。
以下のは、leakしないものの本番導入するのは不安なコードです。(説明は後述)
https://goplay.tools/snippet/cOGJG5PmCG7
package main import ( "fmt" "runtime" "testing" ) func TestSample(t *testing.T) { fmt.Println("begin num goroutine: ", runtime.NumGoroutine()) got, err := Execute("100") t.Log(got) t.Log(err) fmt.Println("end num goroutine: ", runtime.NumGoroutine()) } type response struct { id string res string err error } func Execute(id string) (string, error) { chA := make(chan response) fmt.Println("begin0 num goroutine: ", runtime.NumGoroutine()) go func(id string) { fmt.Println("resA num goroutine: ", runtime.NumGoroutine()) a, err := GetResourceA(id) fmt.Println("resA-1 num goroutine: ", runtime.NumGoroutine()) if err != nil { chA <- response{err: err} return } chA <- response{id: id, res: a, err: err} }(id) fmt.Println("begin1 num goroutine: ", runtime.NumGoroutine()) var resA string errs := make([]error, 0, 1) rr := <-chA fmt.Println("begin3 num goroutine: ", runtime.NumGoroutine()) if rr.err != nil { errs = append(errs, rr.err) } else { resA = rr.res } fmt.Println("begin6 num goroutine: ", runtime.NumGoroutine()) if len(errs) > 0 { return "", fmt.Errorf("%v", errs) } fmt.Println("res:", resA) fmt.Println("begin7 num goroutine: ", runtime.NumGoroutine()) return "", nil } func GetResourceA(id string) (string, error) { return id + "a1", nil }
結果は以下のようになりました
=== RUN TestSample
begin num goroutine: 2
begin0 num goroutine: 2
begin1 num goroutine: 3
resA num goroutine: 3
resA-1 num goroutine: 3
begin3 num goroutine: 2
begin6 num goroutine: 2
res: 100a1
begin7 num goroutine: 2
prog.go:13:
prog.go:14: <nil>
end num goroutine: 2
--- PASS: TestSample (0.00s)
PASS
- goroutineで
GetResourceAを待ち合わせている間はgoroutine数が2から3になって、また2に戻っていることがわかります
つまり以下のようになります
go func(id string) { fmt.Println("resA num goroutine: ", runtime.NumGoroutine()) ←goroutineが新たに起動したので3 a, err := GetResourceA(id) fmt.Println("resA-1 num goroutine: ", runtime.NumGoroutine()) ←ここではまだ結果が返ってきてないので3 <略> }(id) <略> rr := <-chA ←ここで結果が返ってきたのでこの下の結果は2 fmt.Println("begin3 num goroutine: ", runtime.NumGoroutine()) ← 2
複数のgoroutineを起動(leakしないけど不安なコード)
上のgoroutineを2つにしてみます。 また、contextパッケージでtimeoutもできるようにします。
- Timeoutは
time.Millisecondなので1ミリ秒です(短い)
呼びだした二つの関数のどちらかでエラーがでたらそれを出力します。
https://goplay.tools/snippet/r65dbSgNCYj
package main import ( "context" "fmt" "runtime" "testing" "time" ) func TestSample(t *testing.T) { fmt.Println("begin num goroutine: ", runtime.NumGoroutine()) id := "100" got, err := Execute(context.Background(), time.Millisecond, id) t.Log(got) t.Log(err) fmt.Println("end num goroutine: ", runtime.NumGoroutine()) } type response struct { id string res string err error } func Execute(ctx context.Context, timeout time.Duration, id string) (string, error) { ctx, cancel := context.WithTimeout(ctx, timeout) defer cancel() chA := make(chan response) chB := make(chan response) fmt.Println("begin0 num goroutine: ", runtime.NumGoroutine()) go func(id string) { fmt.Println("resA num goroutine: ", runtime.NumGoroutine()) a, err := GetResourceA(ctx, id) fmt.Println("resA-1 num goroutine: ", runtime.NumGoroutine()) if err != nil { chA <- response{err: err} return } chA <- response{id: id, res: a, err: err} }(id) fmt.Println("begin1 num goroutine: ", runtime.NumGoroutine()) go func(id string) { fmt.Println("resB num goroutine: ", runtime.NumGoroutine()) b, err := GetResourceB(ctx, id) fmt.Println("resB-1 num goroutine: ", runtime.NumGoroutine()) if err != nil { chB <- response{err: err} return } chB <- response{id: id, res: b, err: err} }(id) fmt.Println("begin2 num goroutine: ", runtime.NumGoroutine()) var resA, resB string errs := make([]error, 0, 2) for i := 0; i < 2; i++ { fmt.Println("begin2-2 num goroutine: ", runtime.NumGoroutine()) select { case rr := <-chA: fmt.Println("begin3 num goroutine: ", runtime.NumGoroutine()) if rr.err != nil { errs = append(errs, rr.err) continue } resA = rr.res case rr := <-chB: fmt.Println("begin4 num goroutine: ", runtime.NumGoroutine()) if rr.err != nil { errs = append(errs, rr.err) continue } resB = rr.res case <-ctx.Done(): fmt.Println("begin5 num goroutine: ", runtime.NumGoroutine()) errs = append(errs, ctx.Err()) } } fmt.Println("begin6 num goroutine: ", runtime.NumGoroutine()) if len(errs) > 0 { // GetResourceAとGetResourceBのどちらかで失敗したらエラー return "", fmt.Errorf("%v", errs) } fmt.Println("res:", resA, resB) fmt.Println("begin7 num goroutine: ", runtime.NumGoroutine()) return "", nil } func GetResourceA(ctx context.Context, id string) (string, error) { return id + "a1", nil } func GetResourceB(ctx context.Context, id string) (string, error) { return id + "b1", nil }
=== RUN TestSample
begin num goroutine: 2
begin0 num goroutine: 2
begin1 num goroutine: 3
begin2 num goroutine: 4
begin2-2 num goroutine: 4
resB num goroutine: 4
resB-1 num goroutine: 4
begin4 num goroutine: 3
begin2-2 num goroutine: 3
resA num goroutine: 4
resA-1 num goroutine: 3
begin3 num goroutine: 2
begin6 num goroutine: 2
res: 100a1 100b1
begin7 num goroutine: 2
prog.go:16:
prog.go:17: <nil>
end num goroutine: 2
--- PASS: TestSample (0.00s)
PASS
- 結果は上の通り、goroutineが2つ起動したタイミングでgoroutine数は4となり、各goroutineが戻ってきた(selectのcaseに入った)時点で、徐々に減らし、最後はまた2になって終わります
ここまでは何の問題もないように思えます。
複数のgoroutineを起動(明確にleakする場合)
上の関数GetResourceBの中で、10秒Sleepさせてみます。
contextのTimeout時間がtime.Millisecondなので、これだと確実にTimeoutになります。
このコードを実行すると以下のようになります。
https://goplay.tools/snippet/f_40NzONfko
func GetResourceB(ctx context.Context, id string) (string, error) { time.Sleep(10 * time.Second) return id + "b1", nil }
=== RUN TestSample
begin num goroutine: 2
begin0 num goroutine: 2
begin1 num goroutine: 3
begin2 num goroutine: 4
begin2-2 num goroutine: 4
resA num goroutine: 4
resA-1 num goroutine: 4
begin3 num goroutine: 3
begin2-2 num goroutine: 3
resB num goroutine: 4
begin5 num goroutine: 3
begin6 num goroutine: 3
prog.go:15:
prog.go:16: [context deadline exceeded]
end num goroutine: 3
--- PASS: TestSample (0.00s)
PASS
GetResourceBがTimeout以内に終わらなかったので、goroutineが回収されずにgoroutineが3のまま終わっています。- goroutine leakしている状態です
- もし
GetResourceBがなかなか終わらず、かつメモリを多量に消費する関数であれば、`Execute``関数が呼び出されるたびにメモリが回収されずやがては全体のメモリを圧迫することになります
goroutine leakを検出する
上のgoroutine leakを検出するのに、良いパッケージとしてgo.uber.org/goleakというものがあります。
Test関数の最後にgoleak.VerifyNone(t)するだけで検出されます
package main import ( "context" "fmt" "runtime" "testing" "time" "go.uber.org/goleak" ) func TestSample(t *testing.T) { defer goleak.VerifyNone(t) fmt.Println("begin num goroutine: ", runtime.NumGoroutine()) got, err := Execute(context.Background(), time.Millisecond) t.Log(got) t.Log(err) fmt.Println("end num goroutine: ", runtime.NumGoroutine()) }
https://goplay.tools/snippet/3AOHnWHx9Ww
=== RUN TestSample
begin num goroutine: 2
begin0 num goroutine: 2
begin1 num goroutine: 3
begin2 num goroutine: 4
begin2-2 num goroutine: 4
resB num goroutine: 4
resA num goroutine: 3
resA-1 num goroutine: 4
begin3 num goroutine: 3
begin2-2 num goroutine: 3
begin5 num goroutine: 3
begin6 num goroutine: 3
prog.go:18:
prog.go:19: [context deadline exceeded]
end num goroutine: 3
leaks.go:78: found unexpected goroutines:
[Goroutine 8 in state sleep, with time.Sleep on top of the stack:
goroutine 8 [sleep]:
time.Sleep(0x2540be400?)
/usr/local/go-faketime/src/runtime/time.go:194 +0x111
main.GetResourceB(...)
/tmp/sandbox2930251588/prog.go:105
main.Execute.func2({0x4dda2e, 0x3})
/tmp/sandbox2930251588/prog.go:53 +0xff
created by main.Execute
/tmp/sandbox2930251588/prog.go:51 +0x3af
]
--- FAIL: TestSample (0.43s)
FAIL
leaks.go:78: found unexpected goroutines:とはっきり出してくれました
複数のgoroutineを起動(leakさせないように改修)
上のleakの原因はcontextのTimeoutになってmain関数が終わったのに、
GetResourceBが終わらない(キャンセルされない)ためでした。この修正は簡単で、以下のようにTimeoutでcontextのキャンセルがあった時に、
GetResourceBがそのキャンセルを受け取ればよいだけですつまり以下のように修正すればよいです
https://goplay.tools/snippet/YFxohza2aFc
func GetResourceB(ctx context.Context, id string) (string, error) { // time.Sleep(10 * time.Second) select { case <-ctx.Done(): fmt.Println("context Done in GetResourceB") return "", ctx.Err() case <-time.After(10 * time.Second): fmt.Println("sleep finished in GetResourceB") } return id + "b1", nil }
上のselect処理は10秒経過するのか、
ctx.Done()を受け取るか、のどちらかが来れば終わりますこれにより、10秒経過前にcontextがキャンセルされれば
ctx.Done()を受信して終わります。この方法は「Go言語による並行処理」にも書いてあります。
- 私の持つ初版では「4.12 contextパッケージ」にありました。
上のコードを実行してみます。
=== RUN TestSample
begin num goroutine: 2
begin0 num goroutine: 2
begin1 num goroutine: 3
begin2 num goroutine: 4
begin2-2 num goroutine: 4
resA num goroutine: 4
resA-1 num goroutine: 4
begin3 num goroutine: 3
begin2-2 num goroutine: 3
resB num goroutine: 4
begin5 num goroutine: 3
begin6 num goroutine: 3
prog.go:18:
prog.go:19: [context deadline exceeded]
context Done in GetResourceB
resB-1 num goroutine: 3
end num goroutine: 2
--- PASS: TestSample (1.00s)
PASS
goroutine leakが検出されず、goroutine数は起動時と同じ2で終わっています
context Done in GetResourceBが出ているので、contextのキャンセルを受け取ったことがわかります
ちなみに、time.Afterを10秒ではなく、contextのTimeoutより短い10マイクロ秒にすると、GetResourceBはキャンセルされずに終わります
https://goplay.tools/snippet/7WiqTULOmTR
=== RUN TestSample
begin num goroutine: 2
begin0 num goroutine: 2
begin1 num goroutine: 3
resA num goroutine: 3
resA-1 num goroutine: 4
resB num goroutine: 4
begin2 num goroutine: 4
begin2-2 num goroutine: 3
begin3 num goroutine: 3
begin2-2 num goroutine: 3
sleep finished in GetResourceB
resB-1 num goroutine: 3
begin4 num goroutine: 2
begin6 num goroutine: 2
res: 100a1 100b1
begin7 num goroutine: 2
prog.go:18:
prog.go:19: <nil>
end num goroutine: 2
--- PASS: TestSample (1.00s)
PASS
- 今度は、
sleep finished in GetResourceBが出力されました - キャンセルされずに関数が正常終了した場合です
まとめ
go.uber.org/goleakを使うことでgoroutine leakの検出ができるようになりました- 今後も使ってみたいと思います
github pages でWASMを使ったGoのWebツールを動かす【その1】(github pages導入)
目的
WebAssembly 略称 WASM に興味があったので、Go で Web ツールを作成しました。 Web ページを無料で作れるところを探したところ、 github pages が良さそうだったのでこれを使ってみました。
ページの構成
- github pages でWASMを使ったGoのWebツールを動かす【その1】(github pages導入) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす【その2】(WebAssembly導入) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす【その3】(WebAssemblyでの計算機) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす 【その4】(WebAssemblyでのUnixTime変換ツール作成) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす 【その5】(UnixTime変換ツールのTinyGoへの置き換え) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす 【その6】(WASM の Web ツールを github pages で公開する) - ludwig125のブログ
コードと最終的な成果物
コード
最終的に作ったページ
環境と言語
私は Windows 上の WSL で Ubuntu20.04 を使っています。
$cat /etc/os-release NAME="Ubuntu" VERSION="20.04.3 LTS (Focal Fossa)" ID=ubuntu ID_LIKE=debian PRETTY_NAME="Ubuntu 20.04.3 LTS" VERSION_ID="20.04"
なお、この記事に登場する言語は Go、HTML、Javascript ですが、 私は Go は数年の開発経験があるものの、HTML と Javascript はほぼ無知の素人 なので、手探りでの開発となりました。
githubpages の作成
https://docs.github.com/ja/pages/quickstart
を参考に進めます。






この状態で https://ludwig125.github.io/githubpages/ を見ると以下の通りです。

この時点では code は以下の通りです。

このコードをいじるために、ターミナルから操作してみます。
[~/go/src/github.com/ludwig125] $g clone git@github.com:ludwig125/githubpages.git Cloning into 'githubpages'... warning: You appear to have cloned an empty repository. [~/go/src/github.com/ludwig125] $ [~/go/src/github.com/ludwig125] $cd githubpages
gh-pages ブランチに以下のファイルがあります。
[~/go/src/github.com/ludwig125/githubpages] $ls _config.yml index.md
_config.yml を以下のように書き直してみます。
theme: jekyll-theme-cayman title: ludwig125's homepage description: ludwig125's homepage by githubpages
これで commmit して git に push します。 すこし,待つと https://ludwig125.github.io/githubpages/
以下のようにページに上の説明が加わわりました。(title はタブの上にカーソルを重ねると浮かび上がる)

ここまでで、基本的な github pages については理解できました。
github pages でWASMを使ったGoのWebツールを動かす【その2】(WebAssembly導入)
ページの構成
- github pages でWASMを使ったGoのWebツールを動かす【その1】(github pages導入) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす【その2】(WebAssembly導入) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす【その3】(WebAssemblyでの計算機) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす 【その4】(WebAssemblyでのUnixTime変換ツール作成) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす 【その5】(UnixTime変換ツールのTinyGoへの置き換え) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす 【その6】(WASM の Web ツールを github pages で公開する) - ludwig125のブログ
WebAssembly
以下では、WebAssembly を使った Web ページの作成方法を確認します。 この後で、github pages 上で、Go Wasm のページを公開することが目的です。
公式の説明
WebAssembly (abbreviated Wasm) is a binary instruction format for a stack-based virtual machine. Wasm is designed as a portable compilation target for programming languages, enabling deployment on the web for client and server applications.
WebAssembly(略称:Wasm)は、stack-baseの仮想マシン用のバイナリ命令形式です。 Wasmは、プログラミング言語用のポータブルなコンパイルターゲットとして設計されており、クライアントおよびサーバーアプリケーションのWeb上でのdeployを可能にします。
The Wasm stack machine is designed to be encoded in a size- and load-time-efficient binary format. WebAssembly aims to execute at native speed by taking advantage of common hardware capabilities available on a wide range of platforms.
Wasmスタックマシンは、サイズとロード時間の効率的なバイナリ形式でエンコードされるように設計されています。 WebAssemblyは、幅広いプラットフォームで利用可能な一般的なハードウェア機能を活用することで、ネイティブスピードで実行することを目指しています。
補足説明
WebAssembly を使用すると、JavaScript と同じように Rust、C、Go などの言語で Web ツールを作成できます。これにより、既存のライブラリを移植したり、JavaScript で利用できない機能を活用したりできます。
また、WebAssembly はバイナリ形式にコンパイルされるためコードの高速実行が可能になります。 JavaScript より速度を上回ることを目標にしているらしいです。 Go でも、Go1.11 から標準の機能として Go のコードを WebAssembly にコンパイルする機能が追加されました。
今の自分の Go のバージョンは以下の通りでした。
[~/go/src/github.com/ludwig125/githubpages] $go version go version go1.17 linux/amd64
Go WebAssembly
https://github.com/golang/go/wiki/WebAssembly#getting-started
を参考に進めます。
Getting Started
まずは簡単なプログラムを作成します。
main.go
package main
import "fmt"
func main() {
fmt.Println("Hello, WebAssembly!")
}
このコードを WebAssembly 形式で、build するには以下のようにします。
Go にはクロスコンパイルという機能で、別のアーキテクチャや別の OS 向けのバイナリをビルドすることができます。
ここでは、 GOOSをjsに、GOARCH を wasmにすることで、wasm 用のファイルにしています。
また、-o でmain.wasmを指定したので、この名前の実行可能な WebAssembly ファイルが作られることになります。
$ GOOS=js GOARCH=wasm go build -o main.wasm
この main.wasmをブラウザ上で実行するために、Javascript と HTML が必要になります。
Go の最近のバージョンにはデフォルトで wasm 用の javascript(js)が同封されているので、それを以下のように手元に持ってきます。
$ cp "$(go env GOROOT)/misc/wasm/wasm_exec.js" .
また、以下の通り、HTML ファイルを作成します。
<html> <head> <meta charset="utf-8" /> <script src="wasm_exec.js"></script> <script> const go = new Go(); WebAssembly.instantiateStreaming( fetch("main.wasm"), go.importObject ).then((result) => { go.run(result.instance); }); </script> </head> <body></body> </html>
上のコードで重要なのは以下の2つです
<script src="wasm_exec.js"></script>WebAssembly.instantiateStreaming- これは Javascript API で、wasm ファイルの読み込みを可能にします
https://github.com/golang/go/wiki/WebAssembly#getting-started
には、ブラウザがWebAssembly.instantiateStreamingに対応していない場合は polyfillを使うようにと書かれていますが、私の環境では普通に実行できたのでここではこのまま使用しました。
polyfill
この辺の WASM を使う場合の説明は以下が詳しいです
ここまでの段階で以下のファイルが存在します。
[~/go/src/github.com/ludwig125/githubpages] $ls index.html main.go main.wasm* wasm_exec.js
これを Web サーバ上で実行するために、 goexec を使います。
もちろん、別途 Go でサーバプログラムを作ってもいいです( 例:https://go.dev/play/p/pZ1f5pICVbV )が、ここでは公式ドキュメントに従って以下のように goexec でサーバを立てます。
goexec の install(初回のみ)
$ go get -u github.com/shurcooL/goexec
goexec でサーバ起動(ここでは Port 8080 でサーバを立ち上げています)
$ goexec 'http.ListenAndServe(`:8080`, http.FileServer(http.Dir(`.`)))'
注意:うまく動かないときは以下の通り Go の環境設定をする必要があります
また、goexec 実行時に以下のようなエラーが出た場合は、すでに同じ Port で goexec を起動していてバッティングしている可能性があります
(*net.OpError)(&net.OpError{
Op: (string)("listen"),
Net: (string)("tcp"),
Source: (net.Addr)(nil),
Addr: (*net.TCPAddr)(&net.TCPAddr{
IP: (net.IP)(nil),
Port: (int)(8080),
Zone: (string)(""),
}),
Err: (*os.SyscallError)(&os.SyscallError{
Syscall: (string)("bind"),
Err: (syscall.Errno)(0x62),
}),
})
サーバ起動した状態でブラウザでhttp://localhost:8080/にアクセスします。
ちなみに、公式ドキュメントにはhttp://localhost:8080/index.html となっていますが、普通の Web サーバでは http://localhost:8080/のようにスラッシュで終わる URL にアクセスすると自動でindex.htmlを探すようになっているので同じことです。
この Web ページ上で、JavaScript のデバッグコンソールを開きます。
Chrome では、F12 で開けます。

go wasm を github pages で動かす
2021/12/30 の時点で、github pages で Web ページを公開する方法は3通りしかないようです
- master ブランチ
- master ブランチ上の
docs/フォルダ gh-pages ブランチ
github リポジトリでは今後masterではなくmainブランチがデフォルトになったので、今回はmainブランチのdocs/以下に wasm ファイルをおいてみます。
[~/go/src/github.com/ludwig125/githubpages] $ls docs index.html main.go main.wasm* wasm_exec.js
これで、以下の通り、mainブランチのdocs/を選んでSaveします。

30 秒ほど待つと、
https://ludwig125.github.io/githubpages/に更新が反映されて以下の通り、go wasm の結果が見られるようになりました。

これで、githubpages で Go の wasm の Web ページを公開することができるようになりました。
以降、main ブランチを修正すれば、この Web ページも更新されるはずです。
毎回反映を待つのが嫌だったり、ローカルで確認したい場合はgoexecを使えばいいわけです。
github pages でWASMを使ったGoのWebツールを動かす【その3】(WebAssemblyでの計算機)
ページの構成
- github pages でWASMを使ったGoのWebツールを動かす【その1】(github pages導入) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす【その2】(WebAssembly導入) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす【その3】(WebAssemblyでの計算機) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす 【その4】(WebAssemblyでのUnixTime変換ツール作成) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす 【その5】(UnixTime変換ツールのTinyGoへの置き換え) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす 【その6】(WASM の Web ツールを github pages で公開する) - ludwig125のブログ
wasm で計算機
もう少し複雑なケースを見てみます。 そこで、 https://github.com/golang/go/wiki/WebAssembly#getting-started の下にあった https://tutorialedge.net/golang/go-webassembly-tutorial/ を参考に足し算引き算だけの計算機を作ってみます。
ただ、このページは情報が古かったので、自分なりにかなり改変しました。 その結果が以下です。
計算機1(値は固定)
wasm-calculator ブランチをmainから新しく切って修正をします。
index.html
<html> <head> <meta charset="utf-8" /> <title>wasam-calculator</title> <link rel="shortcut icon" href="#" /> <script src="wasm_exec.js"></script> <script> const go = new Go(); WebAssembly.instantiateStreaming( fetch("main.wasm"), go.importObject ).then((result) => { go.run(result.instance); }); </script> </head> <body> <button onClick="add(2,3);" id="addButton">Add</button> <button onClick="subtract(10,3);" id="subtractButton">Subtract</button> </body> </html>
説明
<title>wasam-calculator</title>Web ページのタイトルをつけてみました
Chrome ではこれがタブに表示されます
shortcut iconの役割は、のように設定して任意の画像をタブに出すことです。
<link rel="shortcut icon" href="名前" type="<画像のパス>">
この設定がないと Console 上で以下のようなfavicon.ico 404 (Not Found)のエラーが出ます

button
<button onClick="add(2,3);" id="addButton">Add</button>のように、クリックされるとadd関数に2と3を引数に与えて実行します- この
addとsubtractの処理内容は後述の Go プログラムで定義します
main.go
package main
import (
"fmt"
"syscall/js"
)
func main() {
c := make(chan struct{})
fmt.Println("Hello, WebAssembly!")
registerCallbacks()
<-c
}
func add(this js.Value, args []js.Value) interface{} {
println(args[0].Int() + args[1].Int())
return nil
}
func subtract(this js.Value, args []js.Value) interface{} {
println(args[0].Int() - args[1].Int())
return nil
}
func registerCallbacks() {
js.Global().Set("add", js.FuncOf(add))
js.Global().Set("subtract", js.FuncOf(subtract))
}
説明
上のコードについて説明を書きます。
"syscall/js"Go で js の操作を行うためには syscall/js という標準パッケージを import する必要があります
c := make(chan struct{})と<-cボタンを押すなどのイベント処理をするときにこれが必要になります
- イベント処理では、まず Web ページが表示されて、そのあとユーザがボタンを押して対応する処理が走るいう順番になりますが、Go のプログラムを普通に終わらせてしまうと、ボタンを押されても対応する処理ができずに以下のように
Uncaught Error: Go program has already exitedのエラーが発生します

- channel を使うことで main 関数の実行が終了するのを防ぐことができます。
channel を使う以外に
select {}のように select で待ち続けることでプログラムの終了を防ぐやり方をしている人もいるようですregisterCallbacks()js.Global().Set("property名", property)で Javascript の property を登録することができます- ここで登録する
addとsubtract関数は前述の HTML に対応するものです - Go 側で関数を定義して、イベント発生時に javascript として実行されるものなのでいわゆる Callback 関数です

js.FuncOf()JavaScript の関数を返します
この関数は以前は
js.NewCallbackという名前でしたが、Go1.12 で名前もインターフェースも大きく変わりました。そのため少し古い資料ではjs.FuncOf()ではなくjs.NewCallbackが多く使われていて、混乱の原因になっていますaddとsubtract関数上の
js.FuncOf()の package の定義に沿って、(this js.Value, args []js.Value)を引数として取って、interface{}を返す関数ですargs[0].Int()のように引数2つをそれぞれ Int 型にしてから足しています。- この引数のうち、
thisは JavaScript の global object で、argsはadd(またはsubtract)関数に与えられる引数に相当します
Valueについて
このValueが曲者です。
これが Javascript の世界と Go の世界の橋渡しをするものですが、型が動的なので、 例えば Int に変換しようとしてできない、などの場合にいとも簡単に Panic します
どこで問題が起きたのか非常に分かりにくいです
実行
ここまでで保存して、以下の通り build してサーバを立ち上げます
$ GOOS=js GOARCH=wasm go build -o main.wasm $ goexec 'http.ListenAndServe(`:8080`, http.FileServer(http.Dir(`.`)))'
ブラウザを見ると以下のように、AddボタンやSubtractボタンを押すと Console 上に結果が出力されます

計算機2(値は任意)
決まった数の足し算引き算では面白くないので、TextBox に数字を入力できるようにします。
wasm-calculatorから新たにwasm-calculator2ブランチを切ります
index.html
以下のように修正を加えます
<body>
- <button onClick="add(2,3);" id="addButton">Add</button>
- <button onClick="subtract(10,3);" id="subtractButton">Subtract</button>
+ <input type="text" id="value1" />
+ <input type="text" id="value2" />
+
+ <button onClick="add('value1', 'value2');" id="addButton">Add</button>
+ <button onClick="subtract('value1', 'value2');" id="subtractButton">Subtract</button>
+
+ <div align="left">answer:</div>
+ <div id="answer"></div>
</body>
説明
add(2,3);の代わりに、text入力値をvalue1,value2として受け取り、これをaddやsubtractに渡すようにしました- 後述の Go プログラム側で、
<div id="answer"></div>に計算結果を出力するようにします
main.go
package main import ( "fmt" "strconv" "syscall/js" ) func main() { c := make(chan struct{}) fmt.Println("Hello, WebAssembly!") registerCallbacks() <-c } func registerCallbacks() { js.Global().Set("add", js.FuncOf(add)) js.Global().Set("subtract", js.FuncOf(subtract)) } func add(this js.Value, args []js.Value) interface{} { value1 := textToStr(args[0]) value2 := textToStr(args[1]) int1, _ := strconv.Atoi(value1) int2, _ := strconv.Atoi(value2) fmt.Println("int1:", int1, " int2:", int2) ans := int1 + int2 printAnswer(ans) return nil } func subtract(this js.Value, args []js.Value) interface{} { value1 := textToStr(args[0]) value2 := textToStr(args[1]) int1, _ := strconv.Atoi(value1) int2, _ := strconv.Atoi(value2) fmt.Println("int1:", int1, " int2:", int2) ans := int1 - int2 printAnswer(ans) return nil } func textToStr(v js.Value) string { return js.Global().Get("document").Call("getElementById", v.String()).Get("value").String() } func printAnswer(ans int) { println(ans) js.Global().Get("document").Call("getElementById", "answer").Set("innerHTML", ans) }
説明
textToStrHTML の一行 Text ボックスを
getElementByIdで取得しますこの関数で、Javascript の世界の値を Go の文字列として変換しています
printAnswer計算結果を Print して、そのあと HTML 側で用意した
answerに値をセットします
実行結果

左のテキスト入力欄と右のテキスト入力欄の値の和や差が answer としてブラウザ上にプリントされることが確認できました
[脱線] Go の WASM はライブラリではなくアプリケーションである
GoのWASMはライブラリではなくアプリケーションである この言葉が最初が分かりませんでしたが、以下のような意味だと理解しています
- C/C++/Rust などの言語の WASM では、JavaScript に変換して「ライブラリ」として扱うことができる
- Go の WASM は、「アプリケーション」なので、HTML 側から
実行しないといけない
そのため、イベント処理をするときは Go 側で終了させないようにチャネルで永久に待たせるとか、HTML 側で以下のようにgo.runで Go を実行させる処理が必要になります
const go = new Go();
WebAssembly.instantiateStreaming(fetch("main.wasm"), go.importObject).then((result) => {
go.run(result.instance);
});
計算機3(エラーハンドリング)
前述までで、計算機としての最低限の機能は作れましたが、いくつか重要な欠点があります。
数値のバリデーションチェックがない&エラーハンドリングできていない
テキスト欄に
aやあなど、整数変換ができないものが入力された場合、int1, err := strconv.Atoi("a")の結果、int1 には0が設定されてしまいますこのとき、
errを適切にエラーハンドリングしたいですWeb ページ上でエラーが分かりにくい
上のエラーハンドリングができたら、Web ページにエラーメッセージを出して不正な入力値であることを分かりやすくしたいです
Panic を起こしやすい
js.Global().Get("document").Call("getElementById", v.String()).Get("value").String()
- 例えば
textToStr関数のこの式ですが、getElementByIdで対象の ID が取得できない状態でGetメソッドを呼ぶと Panic を起こします - 同様に、
Get("value")の結果が空の時にStringメソッドを呼んでも Panic となります - 可能な限り Panic で異常終了しないようにしたいです
そこで、以下の資料を参考に次の通り修正しました
- https://golangbot.com/go-webassembly-dom-access/
- https://dev.bitolog.com/go-in-the-browser-using-webassembly/
wasm-calculator2から新たにwasm-calculator3ブランチを切って修正しました
main.go
修正後のコードを最初に書くと以下の通りです。
package main import ( "errors" "fmt" "strconv" "syscall/js" ) func main() { registerCallbacks() <-make(chan struct{}) } func registerCallbacks() { js.Global().Set("calcAdd", calculatorWrapper("add")) js.Global().Set("calcSubtract", calculatorWrapper("subtract")) } func calculatorWrapper(ope string) js.Func { calcFunc := js.FuncOf(func(this js.Value, args []js.Value) interface{} { value1, err := getJSValue(args[0].String()) if err != nil { return wrapResult("", err) } value2, err := getJSValue(args[1].String()) if err != nil { return wrapResult("", err) } fmt.Println("value1:", value1, " value2:", value2) int1, err := strconv.Atoi(value1) if err != nil { return wrapResult("", fmt.Errorf("failed to convert value1 to int: %v", err)) } int2, err := strconv.Atoi(value2) if err != nil { return wrapResult("", fmt.Errorf("failed to convert value2 to int: %v", err)) } var ans int switch ope { case "add": ans = int1 + int2 case "subtract": ans = int1 - int2 default: return wrapResult("", fmt.Errorf("invalid operation: %s", ope)) } fmt.Println("Answer:", ans) if err := setJSValue("answer", ans); err != nil { return wrapResult("", err) } return nil }) return calcFunc } func getJSValue(elemID string) (string, error) { jsDoc := js.Global().Get("document") if !jsDoc.Truthy() { return "", errors.New("failed to get document object") } jsElement := jsDoc.Call("getElementById", elemID) if !jsElement.Truthy() { return "", fmt.Errorf("failed to getElementById: %s", elemID) } jsValue := jsElement.Get("value") if !jsValue.Truthy() { return "", fmt.Errorf("failed to Get value: %s", elemID) } return jsValue.String(), nil } func setJSValue(elemID string, value interface{}) error { jsDoc := js.Global().Get("document") if !jsDoc.Truthy() { return errors.New("failed to get document object") } jsElement := jsDoc.Call("getElementById", elemID) if !jsElement.Truthy() { return fmt.Errorf("failed to getElementById: %s", elemID) } jsElement.Set("innerHTML", value) return nil } func wrapResult(result string, err error) map[string]interface{} { return map[string]interface{}{ "error": err.Error(), "response": result, } }
説明
分かりやすいところから書きます
1. textToStr関数を修正してgetJSValueに改名
func getJSValue(elemID string) (string, error) { jsDoc := js.Global().Get("document") if !jsDoc.Truthy() { return "", errors.New("failed to get document object") } 略 }
- Truthy メソッドはオブジェクトが
false, 0, "", null, undefined, NaNのどれかの時にfalseを返します - これを使うことで Panic を起こす前にエラーを返して呼び出しもとでエラーハンドリングできるようになります
- 関数名はより汎用的に
getJSValueにしました
2. printAnswer関数を修正してsetJSValueに改名
func setJSValue(elemID string, value interface{}) error { jsDoc := js.Global().Get("document") if !jsDoc.Truthy() { return errors.New("failed to get document object") } jsElement := jsDoc.Call("getElementById", elemID) if !jsElement.Truthy() { return fmt.Errorf("failed to getElementById: %s", elemID) } jsElement.Set("innerHTML", value) return nil }
- こちらも
getJSValueと同様にTruthy で逐一判定するようにしました - また、値を設定したい要素の ID を
elemIDとして、設定する値をvalueとして引数にすることで任意の ID に対して設定できるようにしました - 合わせて関数名も print よりも set の方がふさわしいことと、より汎用的にするため
setJSValueに変えました
3. addとsubtract関数を統合してcalculatorWrapperでラップ
func calculatorWrapper(ope string) js.Func { calcFunc := js.FuncOf(func(this js.Value, args []js.Value) interface{} { value1, err := getJSValue(args[0].String()) if err != nil { return wrapResult("", err) } value2, err := getJSValue(args[1].String()) if err != nil { return wrapResult("", err) } fmt.Println("value1:", value1, " value2:", value2) int1, err := strconv.Atoi(value1) if err != nil { return wrapResult("", fmt.Errorf("failed to convert value1 to int: %v", err)) } int2, err := strconv.Atoi(value2) if err != nil { return wrapResult("", fmt.Errorf("failed to convert value2 to int: %v", err)) } var ans int switch ope { case "add": ans = int1 + int2 case "subtract": ans = int1 - int2 default: return wrapResult("", fmt.Errorf("invalid operation: %s", ope)) } fmt.Println("Answer:", ans) if err := setJSValue("answer", ans); err != nil { return wrapResult("", err) } return nil }) return calcFunc } func wrapResult(result string, err error) map[string]interface{} { return map[string]interface{}{ "error": err.Error(), "response": result, } }
- 今までは
js.FuncOfの中身の関数をaddやsubtractとしていましたが、それらをラップしてcalculatorWrapperにしました - これにより、
js.FuncOfのインターフェースに縛られず、今回のopeのように自由に引数を与えることができます - 今回の場合は、
addとsubtractには共通部分が多かったのでこれらを統合して、演算部分だけopeに応じてswitchで条件分岐させるようにしました
wrapResult:
getJSValueやsetJSValueで返したエラーと返り値をこれでラップしていますmap[string]interface{}として返すことで、後述の javascript でエラーハンドリングできるようになります- 今回
wrapResultの中のresponseは全部空にしているので使いません。コールバック関数から値を返したい場合はここに値を設定します
4. registerCallbacksの中で引数を指定してcalculatorWrapperを呼ぶ
func main() { registerCallbacks() <-make(chan struct{}) } func registerCallbacks() { js.Global().Set("calcAdd", calculatorWrapper("add")) js.Global().Set("calcSubtract", calculatorWrapper("subtract")) }
calculatorWrapperで統合したので、addとsubtractは与える引数の違いだけになりましたcalcAddとcalcSubtractは後述のindex.htmlの javascript で使います
<-make(chan struct{})ここは、channel の定義とまとめたほうが簡潔なのでこのようにしました
index.html
index.html は以下のように修正しました。
<html> <head> <meta charset="utf-8" /> <title>wasam-calculator</title> <link rel="shortcut icon" href="#" /> <script src="wasm_exec.js"></script> <script> const go = new Go(); WebAssembly.instantiateStreaming( fetch("main.wasm"), go.importObject ).then((result) => { go.run(result.instance); }); </script> </head> <body> <input type="text" id="value1" /> <input type="text" id="value2" /> <button onClick="addOrErr('value1', 'value2');" id="addButton">Add</button> <button onClick="subtractOrErr('value1', 'value2');" id="subtractButton"> Subtract </button> <div align="left">answer:</div> <div id="answer"></div> <script> function checkError(result) { if (result != null && "error" in result) { console.log("Go return value", result); answer.innerHTML = ""; alert(result.error); } } var addOrErr = function (value1, value2) { var result = calcAdd(value1, value2); checkError(result); }; var subtractOrErr = function (value1, value2) { var result = calcSubtract(value1, value2); checkError(result); }; </script> </body> </html>
説明
- いままで
onClickで直接 Go で書いたaddコールバック関数を呼び出していましたが、ここではaddOrErrという新しく定義した関数を呼び出しています addOrErrの中身を分かりやすいようにcheckError部分を展開して書くと以下の通りです
var addOrErr = function (value1, value2) {
var result = calcAdd(value1, value2);
if (result != null && "error" in result) {
console.log("Go return value", result);
answer.innerHTML = "";
alert(result.error);
}
};
- この関数は、テキスト欄から入力された
value1,value2を引数として取ります - 内部で、Go 側で用意した
calcAddコールバック関数を呼び出してresultを返します - この
resultにはwrapResultで入れたマップデータが入っています - そこで、
result.errorを見ることで Go 側の処理でエラーを返したかどうかが判定できます - ここでは、エラーがある場合は answer の値を空にして、alert でポップアップを出すようにしています
- 【注意点】今回は、
answerが div の HTML タグなのでinnerHTMLを使っていますが、もしanswerがinputやtextareaなどの入力フォームの場合はanswer.value = "";とするのが正しいです
実行結果
テキスト欄に、5と3を入れてAddボタンを押すと以下のように8が表示されます(計算機2と同じ)

テキスト欄に、5と3を入れてSubtractボタンを押すと以下のように2が表示されます(計算機2と同じ)

5の代わりにaなどの数値変換できない文字を入れると、
Go で設定したfailed to convert value1 to int: strconv.Atoi: parsing "a": invalid syntax のエラーがポップアップとして表示されます。
また、Console にGo return valueが表示されていることが分かります

ポップアップを閉じるとanswerの中身が消えています
answerが空になってからポップアップが表示されると思っていましたがよしとします- ここの実行順序は分かっていません

以上で、エラーハンドリングまで対応できるようになりました
github pages でWASMを使ったGoのWebツールを動かす 【その4】(WebAssemblyでのUnixTime変換ツール作成)
ページの構成
- github pages でWASMを使ったGoのWebツールを動かす【その1】(github pages導入) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす【その2】(WebAssembly導入) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす【その3】(WebAssemblyでの計算機) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす 【その4】(WebAssemblyでのUnixTime変換ツール作成) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす 【その5】(UnixTime変換ツールのTinyGoへの置き換え) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす 【その6】(WASM の Web ツールを github pages で公開する) - ludwig125のブログ
Unixtime 変換ツール
上の加算減算しかできない計算機より少しは使い道のありそうな、Unixtime を JST の日付に変換するツールを作ってみました
いきなりコードを載せると以下の通りです
unixtime.go
package main import ( "errors" "fmt" "strconv" "syscall/js" "time" ) func main() { unixtime() <-make(chan struct{}) } func unixtime() { // time zoneを最初に表示させる js.Global().Call("queueMicrotask", js.FuncOf(setTimeZone)) // 二度と使わない関数はメモリを解放する js.FuncOf(setTimeZone).Release() // 一定時間おきにclockを呼び出す js.Global().Call("setInterval", js.FuncOf(clock), "200") getElementByID("in").Call("addEventListener", "input", js.FuncOf(convTime)) } func setTimeZone(this js.Value, args []js.Value) interface{} { t := time.Now() zone, _ := t.Zone() return setJSValue("time_zone", fmt.Sprintf("(%s)", zone)) } func setJSValue(elemID string, value interface{}) error { jsDoc := js.Global().Get("document") if !jsDoc.Truthy() { return errors.New("failed to get document object") } jsElement := jsDoc.Call("getElementById", elemID) if !jsElement.Truthy() { return fmt.Errorf("failed to getElementById: %s", elemID) } jsElement.Set("innerHTML", value) return nil } func getElementByID(targetID string) js.Value { return js.Global().Get("document").Call("getElementById", targetID) } func clock(this js.Value, args []js.Value) interface{} { nowStr, nowUnix := getNow(time.Now()) getElementByID("clock").Set("textContent", nowStr) getElementByID("clock_unixtime").Set("textContent", nowUnix) return nil } func convTime(this js.Value, args []js.Value) interface{} { in := getElementByID("in").Get("value").String() date, err := unixtimeToDate(in) if err != nil { getElementByID("out").Set("value", js.ValueOf("不正な時刻です")) return nil } getElementByID("out").Set("value", js.ValueOf(date)) return nil } func getNow(now time.Time) (string, string) { s := now.Format("2006-01-02 15:04:05") unix := now.Unix() return s, fmt.Sprintf("%d", unix) } func unixtimeToDate(s string) (string, error) { unixtime, err := strconv.Atoi(s) if err != nil { return "", err } date := time.Unix(int64(unixtime), 0) layout := "2006-01-02 15:04:05" // Goの時刻フォーマットではこれで時分秒まで取れる return date.Format(layout), nil }
index.html
<html> <head> <meta charset="utf-8" /> <title>unixtime</title> <link rel="shortcut icon" href="#" /> <script src="wasm_exec.js"></script> <script> const go = new Go(); WebAssembly.instantiateStreaming( fetch("unixtime.wasm"), go.importObject ).then((result) => { go.run(result.instance); }); </script> </head> <body> <h1>UnixTimeを日付に変換するツール</h1> <table border="1" align="center" width="600" height="100"> <tr align="center"> <td> 現在時刻<br /> <div id="time_zone">time_zone</div> </td> <td><div id="clock"></div></td> <td><div id="clock_unixtime"></div></td> </tr> </table> <hr /> <table border="1" align="center" width="300" height="200"> <tr align="center"> <td valign="middle">変換対象の時刻</td> <td><input type="text" id="in" /></td> </tr> <tr align="center"> <td valign="middle">変換後の時刻</td> <td> <input type="text" id="out" /> <button onclick="document.getElementById('out').value = ''"> Clear </button> </td> </tr> </table> </body> </html>
ツールの概要
このツールでは大きく分けて 3 つの機能を作りました
- リアルタイムで現在時刻を表示し続ける機能
- テキスト欄に入力された Unixtime を日付時分秒に変換する機能
- タイムゾーンの表示
順番に見ていきます
説明 1. リアルタイムで現在時刻を表示し続ける機能
Go ではclock関数がこの機能を担当します
- まず
getNow(time.Now())で現在時刻を取得して、それをもとに日付と時分秒のnowStrと Unixtime のnowUnixを作成します - これらをそれぞれ、
getElementByIDで取得した HTML のタグ、clockとclock_unixtimeに設定しています - ポイントは、この
clock関数を、setIntervalを使って 200 ミリ秒ごとに実行されるようにしていることですjs.Global().Call("setInterval", js.FuncOf(clock), "200")
- これにより、Web ツールの表示中、200 ミリ秒ごとに現在時刻が更新されるようになります
HTML 側は以下が対応します
<table border="1" align="center" width="600" height="100"> <tr align="center"> <td>現在時刻</td> <td><div id="clock"></div></td> <td><div id="clock_unixtime"></div></td> </tr> </table>
説明 2. テキスト欄に入力された Unixtime を日付時分秒に変換する機能
Go では、convTime関数がこの機能を担当します
- この関数では、HTML の
inテキスト欄に入力された文字をunixtimeToDate関数で変換し、変換後の文字列を HTML のoutテキスト欄に設定します - この時、Unixtime として間違ったものを
inに入力すると、outに不正な時刻ですと出すようにしました - ポイントは、addEventListenerを使って、
inテキスト欄に入力があったら(inputがあったら)convTimeが実行されるようにしたことです - これにより、
inに入力したのと同時にoutに変換後の値が表示されるようになります
HTML 側は以下のコードが対応します
<table border="1" align="center" width="300" height="200"> <tr align="center"> <td valign="middle">変換対象の時刻</td> <td><input type="text" id="in" /></td> </tr> <tr align="center"> <td valign="middle">変換後の時刻</td> <td> <input type="text" id="out" /> <button onclick="document.getElementById('out').value = ''">Clear</button> </td> </tr> </table>
- テキスト欄
outの文字をクリアするボタンをつけたくなったのですが、これは次のように直下に書いたほうが(Go 側で実装して呼び出すよりも)簡単なのでこうしました <button onclick="document.getElementById('out').value = ''">Clear</button>
説明 3. タイムゾーンの表示
現在時刻の下に、タイムゾーンを表示させました。- Go の time パッケージの
Zoneメソッドを使って取得したものを HTML のtime_zoneタグに出しています - ここでは、「計算機3」の時に作った
setJSValue関数を転用しました - unixtime 全体に言えますが、ここではコードのわかりやすさを優先して、「計算機3」で用いたようなエラーハンドリングはここではしていません
- ここで、ページの読み込み時に
queueMicrotaskを使用しました- この
queueMicrotaskを使った経緯は長くなるので詳しくは後に説明を書きましたが、ここで簡単に説明すると、実行したい処理をキューにつめて後で実行されるようにしています
- この
js.Global().Call("queueMicrotask", js.FuncOf(setTimeZone))
js.FuncOf(setTimeZone).Release()
やっていることは上の
setIntervalとそっくりで、setIntervalが定期的に実行されるのに対して、こちらは単発での実行となりますsetTimeZoneのように、一度呼びだされたら二度と使わない関数は、Releaseメソッドを使ってメモリを解放しておくとメモリの節約になってよいのでjs.FuncOf(setTimeZone).Release()を後ろに書いておきます
参考
- https://pkg.go.dev/syscall/js#Func.Release
- https://zenn.dev/nobonobo/books/85e605893d44ebe7dd3f/viewer/b5ac64d9135e123e367a
動作確認
このプログラムのビルドと実行方法は以下の通りです
[~/go/src/github.com/ludwig125/githubpages/docs/unixtime] $GOOS=js GOARCH=wasm go build -o unixtime.wasm
unixtime.wasm を出力したバイナリファイル名としました
サーバを実行します
goexec 'http.ListenAndServe(`:8080`, http.FileServer(http.Dir(`.`)))'
Web ページを最初に見たときはこんな感じです
現在時刻の部分は 200 ミリ秒ごとにリアルタイムで現在時刻の日付時分秒と Unixtime を表示し続けます
- 「現在時刻」の下に
UTC+9とタイムゾーンが表示されることも確認できます。

「変換対象の時刻」のテキスト欄に Unixtime を入力すると、「変換後の時刻」に変換後の日付時分秒が出力されます

日付に変換できない文字を入れると、エラー文が表示されることも確認できます
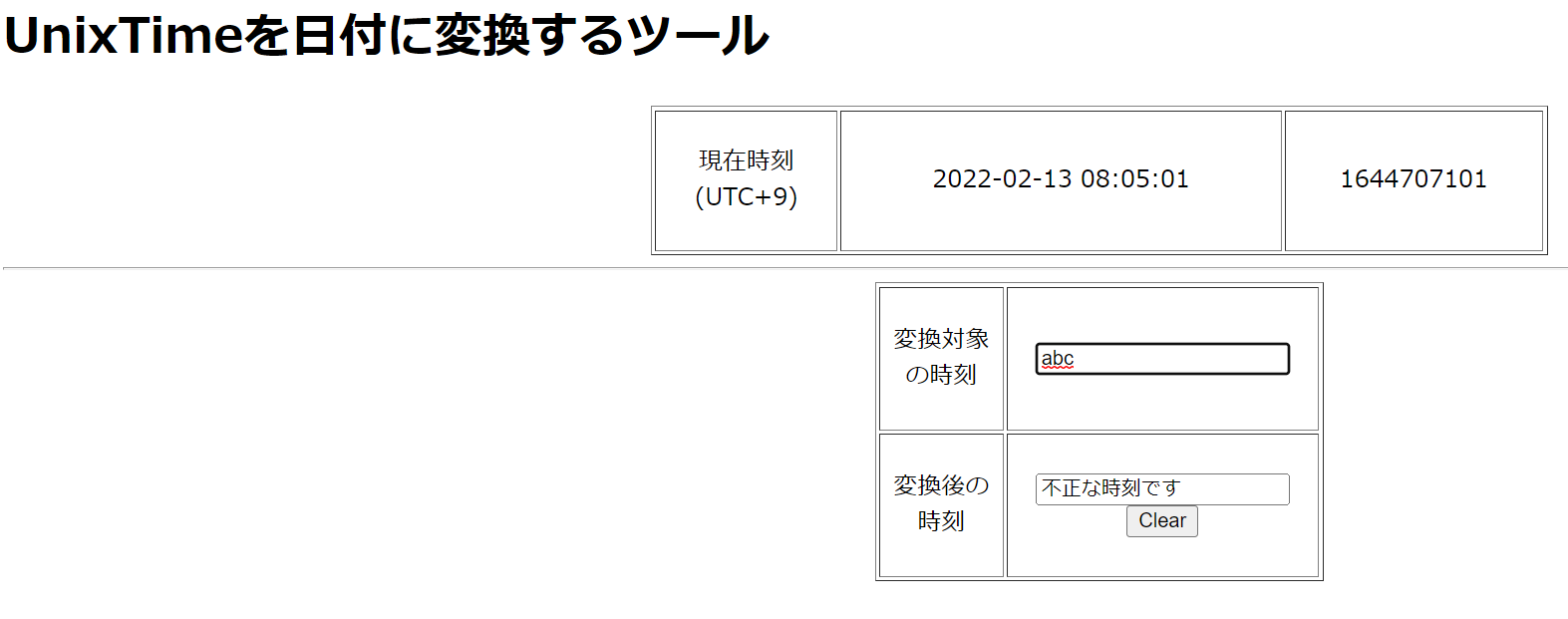
Clearボタンを押すとこの文字は消えます

WebAssembly.instantiateStreaming()が Promise であるということと、queueMicrotask を使った理由について
queueMicrotaskについて上では簡単に説明しただけだったのですが、
ここは個人的にものすごくはまった個所なので少し詳しく説明します。
これは、私が Javascript 未経験だったことも大きいので、詳しい方は読み飛ばしていい箇所です。
WebAssembly.instantiateStreaming()は Promise
まず、この記事で何回も書いてきた WASM ファイルのロード部分をあらためて書きます。
<script src="wasm_exec.js"></script> <script> const go = new Go(); WebAssembly.instantiateStreaming( fetch("XXX.wasm"), go.importObject ).then((result) => { go.run(result.instance); });
ここで使っているWebAssembly.instantiateStreamingですが、
返値 Promise で、次の 2 つのフィールドを持つ ResultObject で解決します。
公式ドキュメントのこちらの記載のとおり、
WebAssembly.instantiateStreamingは Promise、つまり非同期で実行されます。
Promise 処理が成功したらthenのあとの部分が実行されます。
Promise については以下の記事などが詳しいですが、
- https://developer.mozilla.org/ja/docs/Web/JavaScript/Guide/Using_promises
- https://qiita.com/cheez921/items/41b744e4e002b966391a
また、go.importObjectやgo.runですが、これはwasm_exec.jsに定義されたもので、Go ファイルに書いた関数を読み込む部分と実行する部分となります。
つまり、WebAssembly.instantiateStreaming部分でやっていることをあらためて説明すると、
WebAssembly.instantiateStreamingで WASM ファイルをフェッチして Go 関数を Import する処理を Promise で実行- Promise が成功したら then 内の Go の関数が実行
となります。
ここまで当然のことを書いているようですが、
ここで重要なのは、Go に書いた任意の関数を実行しようとしても、
then内に定義しないと「まだその関数が認識されない可能性がある」ということです。
以下問題となる例を書きます。
ページ読み込み時に Go の 関数が実行できない問題
上の Unixtime ツールで作成したsetTimeZone関数は、Web ページ読み込み時にページが実行される地域のタイムゾーン(以下の UTC+9 部分)を Web ページに設定するためにつくりました。

一般的には、Web ページ読み込み時に Javascript の関数を即座に実行する方法として、onloadや、DOMContentLoadedを使った方法が多く見つかります。
最初、setTimeZone関数をこの方法で実行させようとしてうまくいかずはまりました。
うまくいかない例
setTimeZoneという Go の関数を Javascript 側で実行させるために、前述までのイベント処理と同じく、
Go 側で以下のようにsetTimeZoneを Javascript の関数setTimeZoneFuncとして登録します。
js.Global().Set("setTimeZoneFunc", js.FuncOf(setTimeZone))
- ここで
setTimeZoneにsetTimeZoneFuncという名前をつけているのは、単にどちらを指しているのか分かりやすくするためです
この関数を Web ページの読み込み時に実行させるために、
HTML のヘッダー部分に以下のようにwindow.onloadや、document.addEventListener("DOMContentLoaded", 関数)を書いて実行させると、ブラウザのコンソールは次のようになります。
<script> const go = new Go(); WebAssembly.instantiateStreaming( fetch("unixtime.wasm"), go.importObject ).then((result) => { go.run(result.instance); }); window.onload = function () { console.log("test1"); }; document.addEventListener("DOMContentLoaded", function () { console.log("test2"); }); setTimeZoneFunc(); </script>

console.logに書いた文字は表示されるのに、Go 側で定義したsetTimeZoneFuncは
Uncaught ReferenceError: setTimeZoneFunc is not defined
と、関数が存在しないというエラーが出てしまいました。
(time_zoneの div タグは置き換わらずにそのままです)
この理由は、上で書いた通りWebAssembly.instantiateStreamingが Promise で非同期の呼び出しとなっていて、
setTimeZoneFuncを実行されたタイミングではまだロードが終わっておらずこの関数が認識されないためです。
【脱線】test1とtest2の実行順序について
ちなみに上の例で、test1よりもtest2の方を後に書いているのに、ブラウザで順序が入れ変わっている理由ですが、
onload がページや画像などのリソースを読み込んでから処理を実行されるのに対し、DOMContentLoaded は HTML の読み込みと解析が完了したとき、スタイルシート、画像などの読み込みが完了するのを待たずに実行するためです。
以下のページが詳しいです。
【補足】ボタンのクリックなどのイベント処理で関数がうまく実行できた理由
上のように、Javascript でページ読み込み時に Go の関数の呼び出しに失敗してReferenceErrorが出ましたが、
それまでに紹介したボタンのクリックやテキスト欄への入力では、Go の関数が呼び出せました。
この理由は単純で、ボタンのクリックなどを実行する頃には、Go の関数のロードが終わっていて呼び出せる状態になったからです。
実際、上で Uncaught ReferenceError: setTimeZoneFunc is not definedと出た直後に、
コンソールにsetTimeZoneFunc()と入力すると、この時点ではもうロードが終わっていて、正しく実行されます。
time_zone部分がUTC+9に変わりました。

同様の理由で、Javascript で意図的に Sleep をさせたあとに Go の関数を呼び出しても成功します。
以下では、Promise でsetTimeoutをすることで、3 秒待ってからsetTimeZoneFuncを呼び出すコードを書きました。
3秒も待てばロードが終わるので、呼び出しに失敗することがありません。
ただし、これは厳密に WebAssembly.instantiateStreamingの完了を待っているわけではないので良いコードとは言えません。
<script>
const go = new Go();
WebAssembly.instantiateStreaming(
fetch("unixtime.wasm"),
go.importObject
).then((result) => {
go.run(result.instance);
});
async function waitGoLoad() {
console.log("wait 3 seconds...");
await new Promise((s) => setTimeout(s, 3000));
setTimeZoneFunc();
}
waitGoLoad();
ページ読み込み時に Go の関数を実行させる方法 その1
もっとも単純な解決方法は、
WebAssembly.instantiateStreamingの Promise が成功した後、つまりthenのなかのgo.run(result.instance);のあとにsetTimeZoneFuncを設定することです。
こうすれば確実に Go 関数のロードが完了しているので、問題なく呼び出すことができます。
<head> 略 <script src="wasm_exec.js"></script> <script> const go = new Go(); WebAssembly.instantiateStreaming( fetch("unixtime.wasm"), go.importObject ).then((result) => { go.run(result.instance); setTimeZoneFunc(); }); </script> </head>
上の記事のように、go.run(result.instance);後に Web ページ読み込み時に必要な処理を書いていく方法は他にもいくつか見つけたのですが、今回は次のqueueMicrotaskを使う方法を採用しました。
ページ読み込み時に Go の関数を実行させる方法 その2
今回の用途では上の方法でも良かったのですが、
もしこの方法で他の処理も書いていくと<head>の<script>部分がどんどん肥大化していくことになります。
個人的にはこの部分はシンプルにしたい思いがありました。
また、Unixtime ツールの機能のうち、
「1. リアルタイムで現在時刻を表示し続ける機能」が Go のjs.Global().Call("setInterval", js.FuncOf(clock), "200")で完結しているのに、「3. タイムゾーンの表示」を HTML 側でも呼び出さないといけないのがどうにも気に入りませんでした。
そこで、queueMicrotaskを使う方法にしました。
queueMicrotaskの仕様は以下が詳しいです
- https://developer.mozilla.org/ja/docs/Web/API/HTML_DOM_API/Microtask_guide
- https://developer.mozilla.org/en-US/docs/Web/API/queueMicrotask
また、そもそも Macrotasks と Microtasks について知らなかったので以下の記事が大変参考になりました。
- https://hidekazu-blog.com/javascript-macrotasks-microtasks/
- https://ja.javascript.info/event-loop#ref-473
- https://christina04.hatenablog.com/entry/2017/03/13/190000
- https://tech.wwwave.jp/entry/javascript-async-execution
詳しい説明は上の記事に譲るとして、ここでは結論として、queueMicrotask関数にsetTimeZoneを登録しておくことで、Go の実行時に即時にsetTimeZoneを実行することができるようになります。
また、蛇足ですが、上で紹介した
js.Global().Call("setInterval", js.FuncOf(clock), "200")は、200 ミリ秒ごとにclockを呼び出しているので、Web ページ表示後最初の 200 ミリ秒間、一瞬だけ時刻の部分が空になる瞬間があります。
これを防ぐ方法として、clockに対しても以下のようにqueueMicrotaskを使うことで、
Web ページ読み込み時に最初にすぐにclockを実行し、そのあと 200 ミリ秒毎に実行されることで、一瞬空になる瞬間をなくすことができます。
js.Global().Call("queueMicrotask", js.FuncOf(clock))
js.Global().Call("setInterval", js.FuncOf(clock), "200")
繰り返しですが、私は Javascript 初心者なので、このqueueMicrotaskを使った方法が最適なのかどうかまでは確認していません。
github pages でWASMを使ったGoのWebツールを動かす 【その6】(WASM の Web ツールを github pages で公開する)
ページの構成
- github pages でWASMを使ったGoのWebツールを動かす【その1】(github pages導入) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす【その2】(WebAssembly導入) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす【その3】(WebAssemblyでの計算機) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす 【その4】(WebAssemblyでのUnixTime変換ツール作成) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす 【その5】(UnixTime変換ツールのTinyGoへの置き換え) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす 【その6】(WASM の Web ツールを github pages で公開する) - ludwig125のブログ
WASM の Web ツールを github pages で公開する
やっと最後になりました。
WASM の Web ツールを github pages で公開する方法はすでに書きました。
ただ、個人的に気になったのが、 複数の Web ツールを一つのページ以下に置く方法です。
例えばすでに作った計算機と Unixtime ツールを一つのページ以下にぶら下げるにはどうすればいいでしょうか?
github pages の仕様上、すべて/docsディレクトリ以下にツールを配置する必要があります。
ここに置く、Web ツールの Top ページとして、index.htmlを作ると以下のようになるでしょう
<html> <head> <meta charset="utf-8" /> <link rel="shortcut icon" href="#" /> </head> <body> <ul> <li><a href="./calc3_tinygo/calc.html">Calculator</a></li> <li> <a href="./calc3_tinygo_tricky_args/calc.html">Calculator(不具合)</a> </li> <li><a href="./unixtime_tinygo/unixtime.html">Unixtime変換ツール</a></li> </ul> </body> </html>
これまでに作った計算機(TinyGo 版)をCalculator、Unixtime ツール(TinyGo 版)をUnixtime変換ツールとして Top ページ以下に配置しました。
Calculator(不具合)は、前述の TinyGo の//exportを使った場合でも文字列を直接関数に受け渡しする方法をあれこれ考えて、完成させる前に諦めたものです。 もしやる気になったら直すかもしれません(時間かけすぎて挫折してトラウマなのでもう触らない気もします)
ここで気になる点は、複数の Web ツールのディレクトリそれぞれに、wasm_exec.jsや、WebAssembly.instantiateStreamingをするだけのinstantiateWasm.jsを配置するのは無駄に思えることです。
そこで、wasm_exec.jsとinstantiateWasm.jsは/docs以下において、その下の Web ツールから呼びだすようにしました。
以下のような構成では、
$tree docs docs ├── calc3_tinygo │ ├── calc.go │ ├── calc.html │ ├── calc.js │ └── calc.wasm 省略 ├── index.html ├── instantiateWasm.js └── wasm_exec.js
/docs/calc3_tinygoの中のcalc.jsからinstantiateWasm.jsを import するには以下のように../で相対パスを指定します。
import { wasmBrowserInstantiate } from "../instantiateWasm.js";
同様に、/docs/calc3_tinygoの中のcalc.htmlからwasm_exec.jsを呼びだすためには以下のように相対パスを指定すればいいです。
<html> <head> <meta charset="utf-8" /> <title>wasam-calculator</title> <link rel="shortcut icon" href="#" /> <script src="../wasm_exec.js"></script> ← この部分 <script type="module" src="./calc.js"></script> </head> </html>
コード
これでコミットして Push すると、以下のページで Web ツールが見られるようになります
https://ludwig125.github.io/githubpages/

https://ludwig125.github.io/githubpages/calc3_tinygo/calc.html

https://ludwig125.github.io/githubpages/unixtime_tinygo/unixtime.html

以上で最低限の機能は確認できました。
今回、WASM でやりたいことを実現するのにこのような方法を用いましたが、実をいうとこれが最善手なのか分かっていません。 私が Javascript や WASM の賢い書き方に詳しくないだけの可能性もありますが、 とりあえず納得いくものが得られたのでこれで完成とします。
参考
以下参考にさせていただいた記事です
大変助かりました
https://github.com/golang/go/wiki/WebAssembly#getting-started https://tutorialedge.net/golang/go-webassembly-tutorial/ https://github.com/golangbot/webassembly https://wasmbyexample.dev/examples/hello-world/hello-world.go.en-us.html https://golangbot.com/webassembly-using-go/ https://morioh.com/p/385c092f41a9 https://github.com/teamortix/golang-wasm https://github.com/wasmerio/wasmer-go https://itnext.io/webassemply-with-golang-by-scratch-e05ec5230558 https://levelup.gitconnected.com/best-practices-for-webassembly-using-golang-1-15-8dfa439827b8 https://medium.zenika.com/go-1-11-webassembly-for-the-gophers-ae4bb8b1ee03 https://github.com/nlepage/golang-wasm/tree/master/examples https://www.aaron-powell.com/posts/2019-02-08-golang-wasm-5-compiling-with-webpack/ https://blog.suborbital.dev/foundations-wasm-in-golang-is-fantastic https://withblue.ink/2020/10/03/go-webassembly-http-requests-and-promises.html https://www.aaron-powell.com/posts/2019-02-05-golang-wasm-2-writing-go/ js https://hmaster.net/table4.html http://mh.rgr.jp/memo/mh0025.htm wasm clock https://github.com/Yaoir/ClockExample-Go-WebAssembly リアルタイム時刻 https://ja.javascript.info/events-change-input https://www.w3schools.com/howto/howto_html_clear_input.asp ← わかりやすかったです https://dev.bitolog.com/go-in-the-browser-using-webassembly/ ← わかりやすかったです https://golangbot.com/go-webassembly-dom-access/ https://tinygo.org/docs/guides/webassembly/ https://github.com/rfong/wasm-tinygo-hello https://re-engines.com/2021/11/01/go-wasm-promise/ https://www.kabuku.co.jp/developers/annoying-go-wasm https://medium.zenika.com/go-webassembly-binding-structures-to-js-references-4eddd6fd4d23
以下日本語の記事 https://golangtokyo.github.io/codelab/go-webassembly/?index=codelab#3 https://buildersbox.corp-sansan.com/entry/2019/02/14/113000#f-820845f5 https://liginc.co.jp/333868 https://qiita.com/daemonkimura/items/941f9e6f55f6c99cc096 https://tanabebe.hatenablog.com/entry/2019/09/01/124141 https://zenn.dev/nobonobo/books/85e605893d44ebe7dd3f/viewer/b5ac64d9135e123e367a https://zenn.dev/tomi/articles/2020-11-10-go-web11 https://miyanokomiya.tokyo/2018/12/go-wasm/ https://blog.narumium.net/2019/03/09/%E3%80%90go%E3%80%91ver1-12%E3%81%A7%E3%81%AEwebassembly/ https://blog.narumium.net/2019/03/17/%E3%80%90go%E3%80%91wasm%E4%BD%9C%E6%88%90%E3%81%A7%E4%BD%BF%E3%81%86syscall-js%E3%81%AE%E5%9E%8B%E5%A4%89%E6%8F%9B/
github pages でWASMを使ったGoのWebツールを動かす 【その5】(UnixTime変換ツールのTinyGoへの置き換え)
ページの構成
- github pages でWASMを使ったGoのWebツールを動かす【その1】(github pages導入) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす【その2】(WebAssembly導入) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす【その3】(WebAssemblyでの計算機) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす 【その4】(WebAssemblyでのUnixTime変換ツール作成) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす 【その5】(UnixTime変換ツールのTinyGoへの置き換え) - ludwig125のブログ
- github pages でWASMを使ったGoのWebツールを動かす 【その6】(WASM の Web ツールを github pages で公開する) - ludwig125のブログ
TinyGo への置き換え
TinyGoのInstallと実行
Installなどはこちらのページにまとめました
TinyGo の実行方法
上で作った Unixtime ツールを TinyGo に置き換えてみます。
以下の方法で TinyGo として Buid できます。(通常の Go に比べて若干 Build に時間がかかるような気がします)
$tinygo build -o unixtime.wasm -target wasm unixtime.go
cp $(tinygo env TINYGOROOT)/targets/wasm_exec.js .
これだけで TinyGo として WASM で実行できます。
[~/go/src/github.com/ludwig125/githubpages/unixtime_tinygo] $goexec 'http.ListenAndServe(`:8080`, http.FileServer(http.Dir(`.`)))'
ただ、http://localhost:8080/ を見ると、一見問題ないように見えますが、 「変換対象の時刻」に Unixtime を入れると Console にエラーがでます。 (処理自体は問題なく行われます)

エラー:syscall/js.finalizeRef not implemented
このエラー原因について詳しくは以下を見ると良いのですが、
TinyGo のバグなので、TinyGo のwasm_exec.jsが修正されるまでは、以下のようにindex.html側に書いておくとこのエラーがなくなります。
const go = new Go();
// TinyGoのバグを無視するため
// https://github.com/tinygo-org/tinygo/issues1140#issuecomment-671261465
go.importObject.env["syscall/js.finalizeRef"] = ()=> {};
WebAssembly.instantiateStreaming(
fetch("unixtime.wasm"),
go.importObject
).then((result) => {
参考:
これでエラー文が出なくなります。
TinyGo のバイナリサイズ
2つのバイナリサイズを比べてみます
[~/go/src/github.com/ludwig125/githubpages/unixtime] $GOOS=js GOARCH=wasm go build -o unixtime.wasm [~/go/src/github.com/ludwig125/githubpages/unixtime] $ls -l 合計 2096 -rw-r--r-- 1 ludwig125 ludwig125 1247 2月 14 06:58 index.html -rw-r--r-- 1 ludwig125 ludwig125 2103 2月 18 06:08 unixtime.go -rwxr-xr-x 1 ludwig125 ludwig125 2113909 2月 18 06:08 unixtime.wasm* -rw-r--r-- 1 ludwig125 ludwig125 18346 2月 14 06:10 wasm_exec.js
[~/go/src/github.com/ludwig125/githubpages/unixtime_tinygo] $tinygo build -o unixtime.wasm -target wasm unixtime.go [~/go/src/github.com/ludwig125/githubpages/unixtime_tinygo] $ls -l 合計 464 -rw-r--r-- 1 ludwig125 ludwig125 1437 2月 17 06:39 index.html -rw-r--r-- 1 ludwig125 ludwig125 2103 2月 18 06:08 unixtime.go -rwxr-xr-x 1 ludwig125 ludwig125 447857 2月 18 06:09 unixtime.wasm* -rw-r--r-- 1 ludwig125 ludwig125 15929 2月 14 06:30 wasm_exec.js
私の環境では、ほぼ同じコードでも、TinyGo は Go と比べてunixtime.wasm*のバイナリサイズが 1/4 以下になっていました。
TinyGo の速度
バイナリサイズが小さいということは、当然 WASM として Fetch したり Load するのも速くなるはずです。
通常の Go と TinyGo の Load までの時間を計測するために、それぞれのindex.htmlに以下のコードを追加してみます。
<script>
var start = performance.now(); // 追加部分
const go = new Go();
WebAssembly.instantiateStreaming(
fetch("unixtime.wasm"),
go.importObject
).then((result) => {
go.run(result.instance);
var end = performance.now(); // 追加部分
console.log("latency of load and run wasm %f ms", end - start); // 追加部分
});
</script>
https://developer.mozilla.org/ja/docs/Web/API/Performance/now
こちらのパフォーマンス計測用の関数を使います
WebAssembly.instantiateStreamingの前をstartgo.run(result.instance);の後をend
としてこの差分を測ってみます。
ついでに、Go の方の関数にも Latency を計測するために以下の部分を追記します。
func convTime(this js.Value, args []js.Value) interface{} { start := time.Now() defer func() { fmt.Println("convTime latency:", time.Since(start)) }() 略
これで、Go と TinyGoUnixtime の Web ページをそれぞれ順番に見てみます。
通常の Go

TinyGo

注意点
- Go のあとに TinyGo のページを読み込みなおすときは、Chrome のキャッシュに残っていておかしなエラーが出る場合があります。この場合はキャッシュをクリアしてページを再読み込みするために、
Ctrl+Shift+Rでページを更新するといいです
WASM の Fetch から実行までの時間は
- Go: 52.10000002384186 ms
- TinyGo: 16 ms
となりました。
やはり、起動までの時間は TinyGo の方が短くなっています。 今回は小さなプログラムなので、この程度の差ですが、大きなプログラムになると実行までの時間はさらに変わってくるかも知れません。
一方で、convTimeの実行速度はあまり変わりませんでした。
これは意外でした。
ひとたびバイナリとして読み込んでメモリに乗ってしまえばあとはそんなに変わらないものなのか、それとも実行している関数がそんなに違いが見られる類のものではなかったのかも知れませんが分かりません。
export を利用した TinyGo コードの書き換え
TinyGo は Go と同じコードをそのまま使えますが、TinyGo ならではのexportの機能を使うとコードをより直接に呼びだすことができます
https://tinygo.org/docs/guides/webassembly/
If you have used explicit exports, you can call them by invoking them under the wasm.exports namespace. See the export directory in the examples for an example of this.
とあるとおり、以下のように Go の関数に//export 関数名をつけるだけで、なんと Javascript 側から呼びだすことができます。
//export multiply func multiply(x, y int) int { return x * y; }
- ここで、
//exportの//とexportの間に半角スペースを入れると認識されないので、くっつけて書くことを注意してください** - ちなみに
//exportは以前は//go:exportでしたが、2020 年に変わったので少し古い資料を見ると//go:exportとなっていることがあります
javascript からの呼び出し方法
// Calling the multiply function:
console.log("multiplied two numbers:", wasm.exports.multiply(5, 3));
このmultiply関数はこれまでの WASM の Go の書き方の
multiply(this js.Value, args []js.Value) interface{} のような形にしなくて済むというのが最大の利点です。
//exportを使った場合の大きな問題点もあるのですがそれは後述します
この機能を使うと、Unixtime ツールの例えばsetTimeZone関数は以下のようにシンプルになり、
//export setTimeZone func setTimeZone() { t := time.Now() zone, _ := t.Zone() setJSValue("time_zone", fmt.Sprintf("(%s)", zone)) }
index.html 側では以下のように呼びだすことができます。
const go = new Go();
WebAssembly.instantiateStreaming(fetch("unixtime.wasm"), go.importObject).then(
(result) => {
go.run(result.instance);
result.instance.exports.setTimeZone();
}
);
この方式で、go.run(result.instance);のあとに必要な処理をつらつら書いても良いのですが、これだとindex.htmlの<head>の<script>部分が肥大するので、以下の資料を参考にindex.jsファイルに切り出してみます。
package main import ( "errors" "fmt" "strconv" "syscall/js" "time" ) func main() {} //export setTimeZone func setTimeZone() { t := time.Now() zone, _ := t.Zone() setJSValue("time_zone", fmt.Sprintf("(%s)", zone)) } func setJSValue(elemID string, value interface{}) error { // 元と同じ } func getElementByID(targetID string) js.Value { // 元と同じ } //export clock func clock() { nowStr, nowUnix := getNow(time.Now()) getElementByID("clock").Set("textContent", nowStr) getElementByID("clock_unixtime").Set("textContent", nowUnix) } //export convTime func convTime() { in := getElementByID("in").Get("value").String() date, err := unixtimeToDate(in) if err != nil { getElementByID("out").Set("value", js.ValueOf("不正な時刻です")) return } getElementByID("out").Set("value", js.ValueOf(date)) } // 以降、元と同じ
「//export」を使うことでかなりシンプルになりました。
TinyGo の export を使えば Javascript 側から Go の関数を直接呼びだすことができます。
コールバック関数が呼び出されたときのために Go のプログラムを永久に終わらせないようにするために、main関数内でチャネルを使っていましたがその必要もなくなりました。
Go の関数の呼び出し側である、HTML と Javascript も修正します。
前述の通り head 部分を見やすくするために、以下を参考に修正しました。
まず、WASM ファイルのインスタンス生成部分を別のファイルにします。
instantiateWasm.js
export const wasmBrowserInstantiate = async (wasmModuleUrl, importObject) => {
let response = undefined;
if (!importObject) {
importObject = {
env: {
abort: () => console.log("Abort!"),
},
};
}
response = await WebAssembly.instantiateStreaming(
fetch(wasmModuleUrl),
importObject
);
return response;
};
// polyfillを定義した場合
if (WebAssembly.instantiateStreaming) {
response = await WebAssembly.instantiateStreaming(
fetch(wasmModuleUrl),
importObject
);
} else {
const fetchAndInstantiateTask = async () => {
const wasmArrayBuffer = await fetch(wasmModuleUrl).then((response) =>
response.arrayBuffer()
);
return WebAssembly.instantiate(wasmArrayBuffer, importObject);
};
response = await fetchAndInstantiateTask();
}
一方、呼び出し側のindex.htmlから、WASM の呼び出し部分を切り出して別のファイルにすると以下のようになります。
index.js
import { wasmBrowserInstantiate } from "./instantiateWasm.js";
const go = new Go(); // Defined in wasm_exec.js. Don't forget to add this in your index.html.
// TinyGoのバグを無視するため
// https://github.com/tinygo-org/tinygo/issues/1140#issuecomment-671261465
go.importObject.env["syscall/js.finalizeRef"] = () => {};
const runWasm = async () => {
// Get the importObject from the go instance.
const importObject = go.importObject;
// wasm moduleのインスタンスを作成
const wasmModule = await wasmBrowserInstantiate(
"./unixtime.wasm",
importObject
);
go.run(wasmModule.instance);
wasmModule.instance.exports.setTimeZone();
setInterval(wasmModule.instance.exports.clock, 200);
document
.getElementById("in")
.addEventListener("input", wasmModule.instance.exports.convTime);
};
runWasm();
- インスタンス生成部分とメインの処理部分を分離して分かりやすくなりました
- (
wasmModule.instance.exports.部分がやや鬱陶しいですが、)Go の関数を Javascript ネイティブの関数のように扱うことができるようになったため、実行方法も Javascript の書き方になっています
最後に、このindex.jsをindex.htmlから呼びだせば終わりです。
<head> <meta charset="utf-8" /> <title>unixtime</title> <link rel="shortcut icon" href="#" /> <script src="./wasm_exec.js"></script> <script type="module" src="./index.js"></script> </head>
かなり見やすくなったかと思います。
export を使った関数の限界
とても素敵な機能に思える TinyGo の//exportですが、これを書いている 2022 年 3 月の現時点ではとても大きな問題があります。
それは、WASM では直接文字列をやりとりできないことです
以下が WASM の扱える型の種類です。 https://github.com/WebAssembly/design/blob/main/Semantics.md#types
WebAssembly has the following value types: i32: 32-bit integer i64: 64-bit integer f32: 32-bit floating point f64: 64-bit floating point
そのため、例えば以下のような方法で直接文字列を関数に渡したり返してもらうことはできません
// 以下のようにTinyGoで関数を使うことはできない //export printMessage func printMessage(s string) { // stringを受け取ることができない fmt.Println("hello:", s) } //export returnString func returnString() string { return "hello" // stringを返すこともできない }
int 型は扱えるので、変数のアドレスと長さを計算してそれを関数に渡す方法があるにはありますが、とても分かりやすいとは言えません。
参考
- https://github.com/tinygo-org/tinygo/issues/645
- https://github.com/tinygo-org/tinygo/issues/411#issuecomment-503066868
- https://www.alcarney.me/blog/2020/passing-strings-between-tinygo-wasm/
- https://stackoverflow.com/questions/41353389/how-can-i-return-a-javascript-string-from-a-webassembly-function
- https://github.com/tinygo-org/tinygo/issues/1824
- https://wasmbyexample.dev/examples/webassembly-linear-memory/webassembly-linear-memory.go.en-us.html
- https://nulab.com/ja/blog/nulab/basic-webassembly-begginer/
- https://zenn.dev/summerwind/articles/96f2aae05b6614
また仮に文字列を1つ渡せても2つ以上はできないので、その場合は json などでデコードして渡す必要があります
TinyGo での json 参考
- https://github.com/tinygo-org/tinygo/issues/447
- https://github.com/mailru/easyjson
- https://www.sambaiz.net/article/193/
- https://stackoverflow.com/questions/40587860/using-easyjson-with-golang/44757748
- https://github.com/tinygo-org/tinygo/pull/2314
以上の理由から、TinyGo でも//exportを使いまくるわけにはいかず、文字列のやり取りをする際は素直に js パッケージを使って Javascript とやり取りしたほうが便利な場面が多そうです。